Publications
2024
-
 Material Palette: Extraction of Materials from a Single ImageLopes, Ivan, Pizzati, Fabio, and Charette, RaoulIn CVPR 2024
Material Palette: Extraction of Materials from a Single ImageLopes, Ivan, Pizzati, Fabio, and Charette, RaoulIn CVPR 2024In this paper, we propose a method to extract physically-based rendering (PBR) materials from a single real-world image. We do so in two steps: first, we map regions of the image to material concepts using a diffusion model, which allows the sampling of texture images resembling each material in the scene. Second, we benefit from a separate network to decompose the generated textures into Spatially Varying BRDFs (SVBRDFs), providing us with materials ready to be used in rendering applications. Our approach builds on existing synthetic material libraries with SVBRDF ground truth, but also exploits a diffusion-generated RGB texture dataset to allow generalization to new samples using unsupervised domain adaptation (UDA). Our contributions are thoroughly evaluated on synthetic and real-world datasets. We further demonstrate the applicability of our method for editing 3D scenes with materials estimated from real photographs. The code and models will be made open-source.
@inproceedings{matpal, title = {Material Palette: Extraction of Materials from a Single Image}, author = {Lopes, Ivan and Pizzati, Fabio and de Charette, Raoul}, booktitle = {CVPR}, year = {2024}, } -
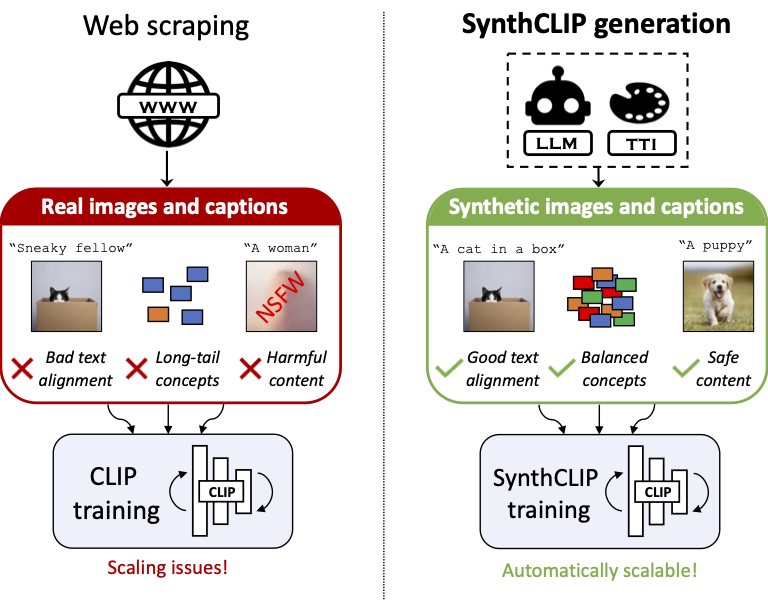 SynthCLIP: Are We Ready for a Fully Synthetic CLIP Training?Hammoud, Hasan Abed Al Kader, Itani, Hani, Pizzati, Fabio, Torr, Philip, Bibi, Adel, and Ghanem, Bernardunder review 2024
SynthCLIP: Are We Ready for a Fully Synthetic CLIP Training?Hammoud, Hasan Abed Al Kader, Itani, Hani, Pizzati, Fabio, Torr, Philip, Bibi, Adel, and Ghanem, Bernardunder review 2024We present SynthCLIP, a novel framework for training CLIP models with entirely synthetic text-image pairs, significantly departing from previous methods relying on real data. Leveraging recent text-to-image (TTI) generative networks and large language models (LLM), we are able to generate synthetic datasets of images and corresponding captions at any scale, with no human intervention. With training at scale, SynthCLIP achieves performance comparable to CLIP models trained on real datasets. We also introduce SynthCI-30M, a purely synthetic dataset comprising 30 million captioned images. Our code, trained models, and generated data are released.
@article{synthCLIP, title = {SynthCLIP: Are We Ready for a Fully Synthetic CLIP Training?}, author = {Hammoud, Hasan Abed Al Kader and Itani, Hani and Pizzati, Fabio and Torr, Philip and Bibi, Adel and Ghanem, Bernard}, journal = {under review}, year = {2024}, } -
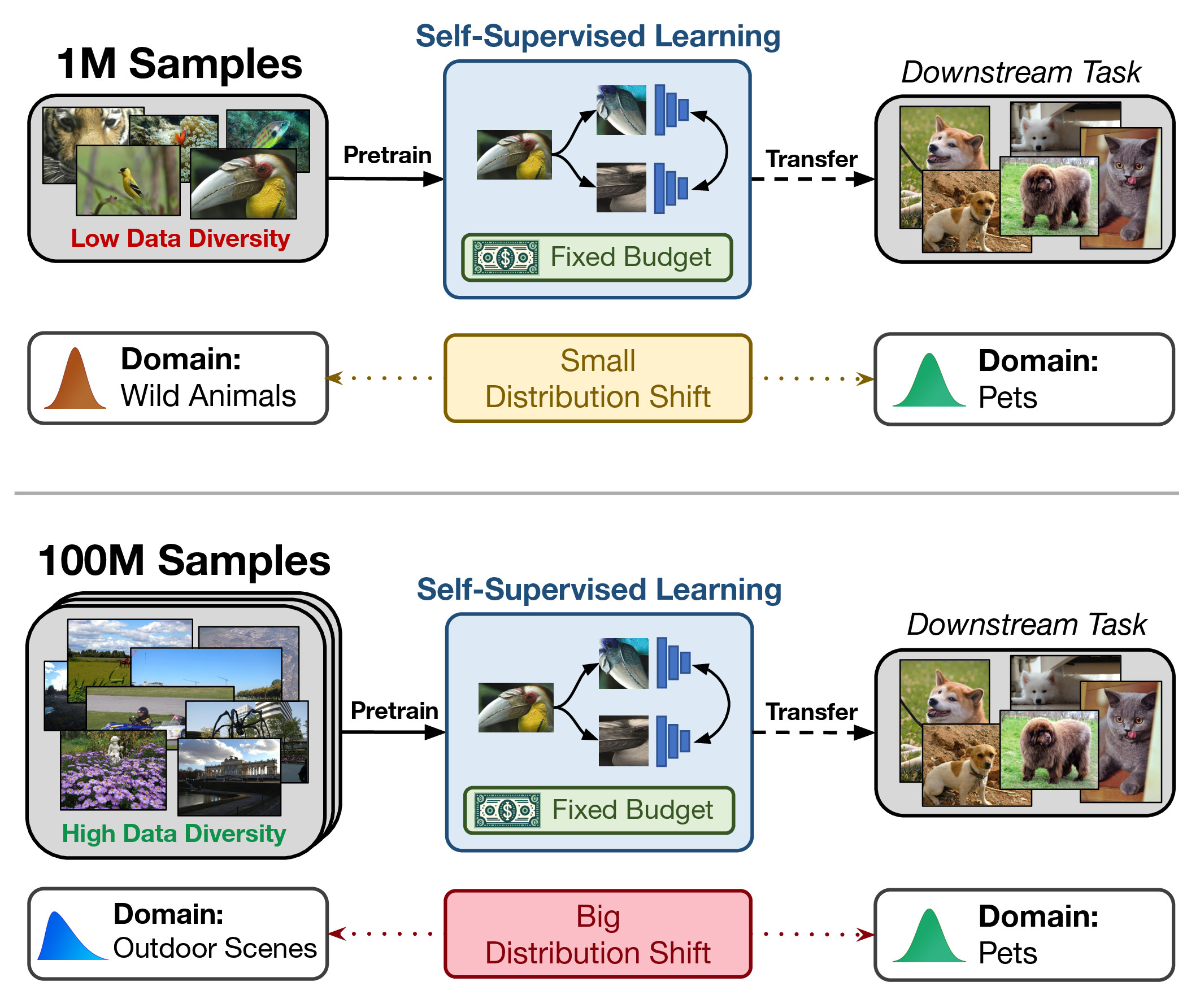 On Pretraining Data Diversity for Self-Supervised LearningHammoud, Hasan Abed Al Kader, Das, Tuhin, Pizzati, Fabio (shared first author), Torr, Philip, Bibi, Adel, and Ghanem, Bernardunder review 2024
On Pretraining Data Diversity for Self-Supervised LearningHammoud, Hasan Abed Al Kader, Das, Tuhin, Pizzati, Fabio (shared first author), Torr, Philip, Bibi, Adel, and Ghanem, Bernardunder review 2024We explore the impact of training with more diverse datasets, characterized by the number of unique samples, on the performance of self-supervised learning (SSL) under a fixed computational budget. Our findings consistently demonstrate that increasing pretraining data diversity enhances SSL performance, albeit only when the distribution distance to the downstream data is minimal. Notably, even with an exceptionally large pretraining data diversity achieved through methods like web crawling or diffusion-generated data, among other ways, the distribution shift remains a challenge. Our experiments are comprehensive with seven SSL methods using large-scale datasets such as ImageNet and YFCC100M amounting to over 200 GPU days.
@article{budgetssl, title = {On Pretraining Data Diversity for Self-Supervised Learning}, author = {Hammoud, Hasan Abed Al Kader and Das, Tuhin and Pizzati, Fabio (shared first author) and Torr, Philip and Bibi, Adel and Ghanem, Bernard}, journal = {under review}, year = {2024}, }
2023
-
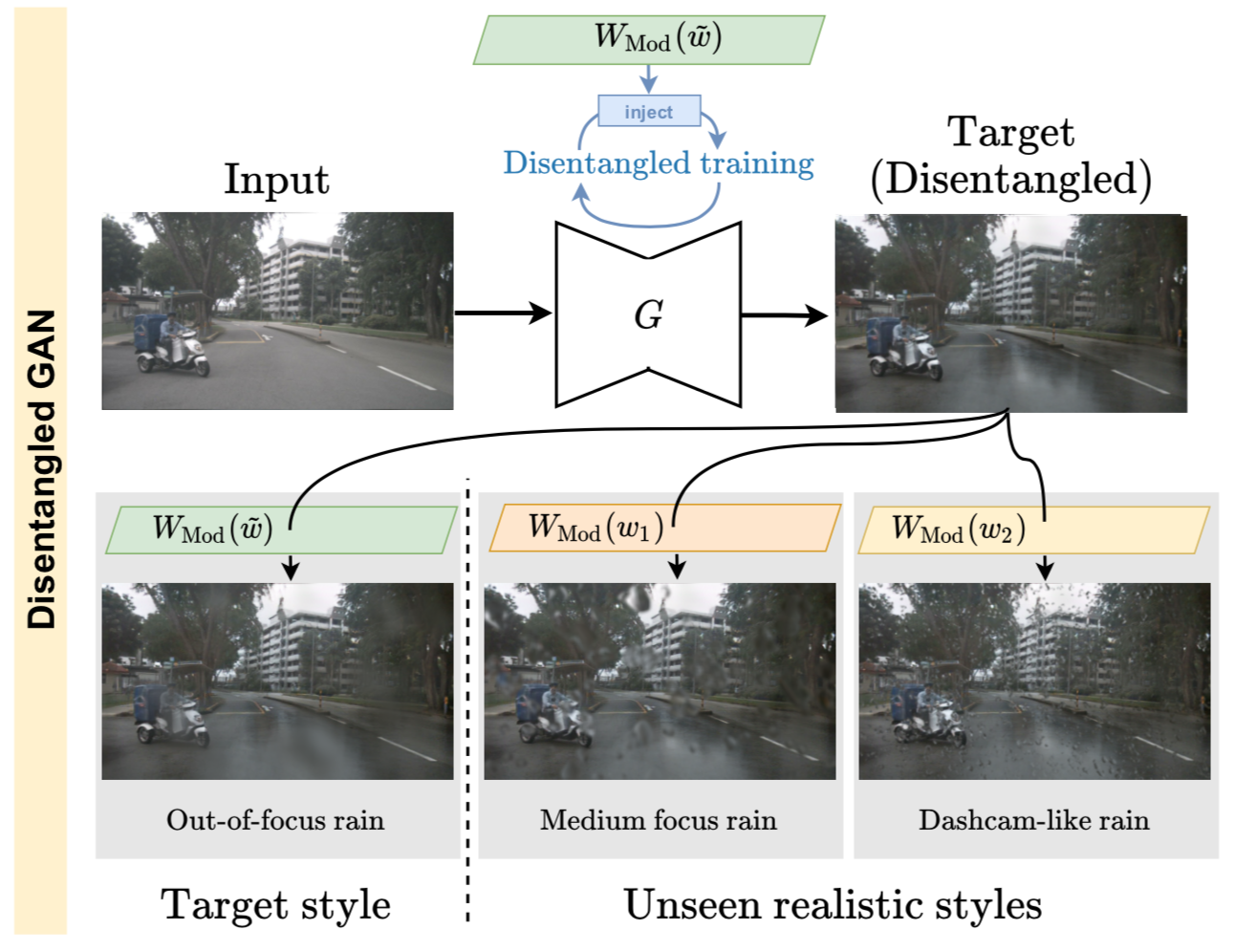 Physics-informed guided disentanglement for generative networksPizzati, Fabio, Cerri, Pietro, and Charette, RaoulT-PAMI 2023
Physics-informed guided disentanglement for generative networksPizzati, Fabio, Cerri, Pietro, and Charette, RaoulT-PAMI 2023Image-to-image translation (i2i) networks suffer from entanglement effects in presence of physics-related phenomena in target domain (such as occlusions, fog, etc), lowering altogether the translation quality, controllability and variability. In this paper, we build upon collection of simple physics models and present a comprehensive method for disentangling visual traits in target images, guiding the process with a physical model that renders some of the target traits, and learning the remaining ones. Because it allows explicit and interpretable outputs, our physical models (optimally regressed on target) allows generating unseen scenarios in a controllable manner. We also extend our framework, showing versatility to neural-guided disentanglement. The results show our disentanglement strategies dramatically increase performances qualitatively and quantitatively in several challenging scenarios for image translation.
@article{arxiv, title = {Physics-informed guided disentanglement for generative networks}, author = {Pizzati, Fabio and Cerri, Pietro and de Charette, Raoul}, journal = {T-PAMI}, year = {2023}, }
2022
-
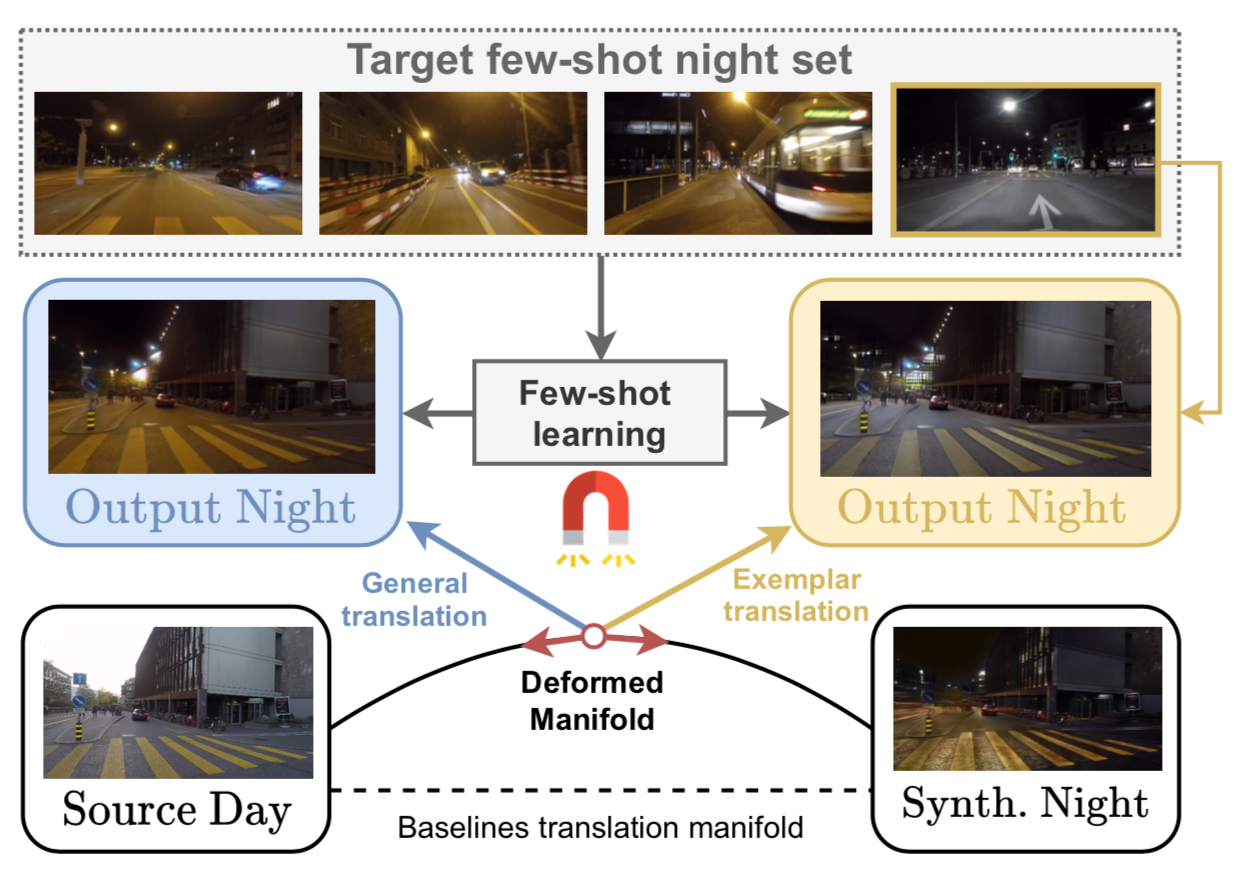 ManiFest: Manifold Deformation for Few-shot Image TranslationPizzati, Fabio, Lalonde, Jean-François, and Charette, RaoulIn ECCV 2022
ManiFest: Manifold Deformation for Few-shot Image TranslationPizzati, Fabio, Lalonde, Jean-François, and Charette, RaoulIn ECCV 2022Most image-to-image translation methods require a large number of training images, which restricts their applicability. We instead propose ManiFest: a framework for few-shot image translation that learns a context-aware representation of a target domain from a few images only. To enforce feature consistency, our framework learns a style manifold between source and proxy anchor domains (assumed to be composed of large numbers of images). The learned manifold is interpolated and deformed towards the few-shot target domain via patch-based adversarial and feature statistics alignment losses. All of these components are trained simultaneously during a single end-to-end loop. In addition to the general few-shot translation task, our approach can alternatively be conditioned on a single exemplar image to reproduce its specific style. Extensive experiments demonstrate the efficacy of ManiFest on multiple tasks, outperforming the state-of-the-art on all metrics and in both the general- and exemplar-based scenarios.
@inproceedings{manifest, title = {{ManiFest: Manifold Deformation for Few-shot Image Translation}}, author = {Pizzati, Fabio and Lalonde, Jean-François and de Charette, Raoul}, booktitle = {ECCV}, year = {2022}, } -
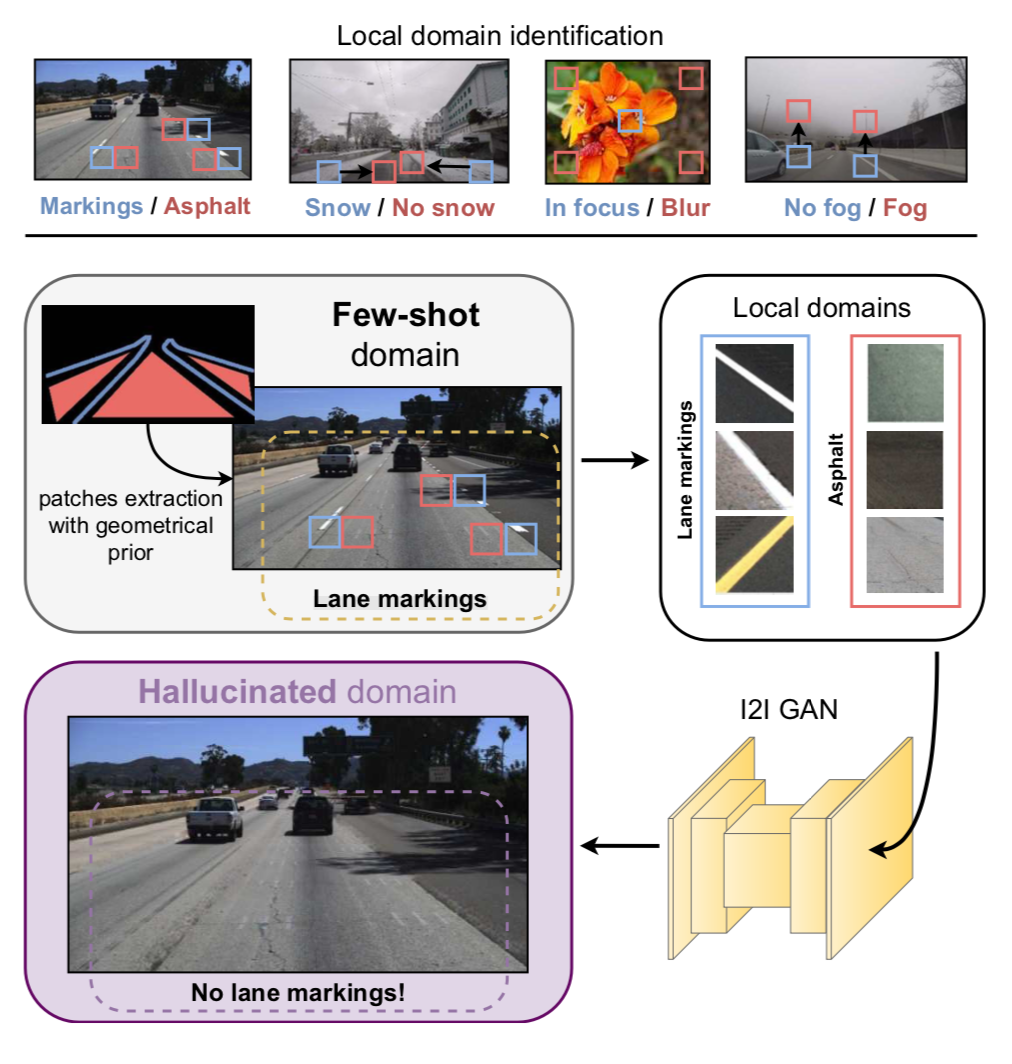 Leveraging Local Domains for Image-to-Image TranslationDell’Eva, Anthony, Pizzati, Fabio, Bertozzi, Massimo, and Charette, RaoulIn VISAPP (best paper award) 2022
Leveraging Local Domains for Image-to-Image TranslationDell’Eva, Anthony, Pizzati, Fabio, Bertozzi, Massimo, and Charette, RaoulIn VISAPP (best paper award) 2022Image-to-image (i2i) networks struggle to capture local changes because they do not affect the global scene structure. For example, translating from highway scenes to offroad, i2i networks easily focus on global color features but ignore obvious traits for humans like the absence of lane markings. In this paper, we leverage human knowledge about spatial domain characteristics which we refer to as ’local domains’ and demonstrate its benefit for image-to-image translation. Relying on a simple geometrical guidance, we train a patch-based GAN on few source data and hallucinate a new unseen domain which subsequently eases transfer learning to target. We experiment on three tasks ranging from unstructured environments to adverse weather. Our comprehensive evaluation setting shows we are able to generate realistic translations, with minimal priors, and training only on a few images. Furthermore, when trained on our translations images we show that all tested proxy tasks are significantly improved, without ever seeing target domain at training.
@inproceedings{visapp, title = {Leveraging Local Domains for Image-to-Image Translation}, author = {Dell'Eva, Anthony and Pizzati, Fabio and Bertozzi, Massimo and de Charette, Raoul}, booktitle = {VISAPP (best paper award)}, year = {2022}, }
2021
-
 CoMoGAN: continuous model-guided image-to-image translationPizzati, Fabio, Cerri, Pietro, and Charette, RaoulIn CVPR (oral) 2021
CoMoGAN: continuous model-guided image-to-image translationPizzati, Fabio, Cerri, Pietro, and Charette, RaoulIn CVPR (oral) 2021CoMoGAN is a continuous GAN relying on the unsupervised reorganization of the target data on a functional manifold. To that matter, we introduce a new Functional Instance Normalization layer and residual mechanism, which together disentangle image content from position on target manifold. We rely on naive physics-inspired models to guide the training while allowing private model/translations features. CoMoGAN can be used with any GAN backbone and allows new types of image translation, such as cyclic image translation like timelapse generation, or detached linear translation. On all datasets, it outperforms the literature.
@inproceedings{cvpr, title = {{CoMoGAN}: continuous model-guided image-to-image translation}, author = {Pizzati, Fabio and Cerri, Pietro and de Charette, Raoul}, booktitle = {CVPR (oral)}, year = {2021}, }
2020
-
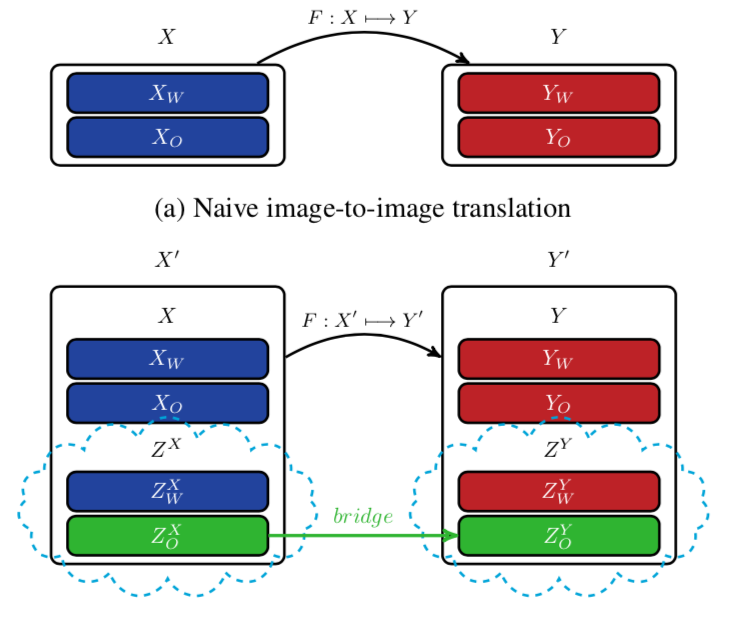 Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain AdaptationPizzati, Fabio, Charette, Raoul, Zaccaria, Michela, and Cerri, PietroIn WACV 2020
Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain AdaptationPizzati, Fabio, Charette, Raoul, Zaccaria, Michela, and Cerri, PietroIn WACV 2020Image-to-image translation architectures may have limited effectiveness in some circumstances. For example, while generating rainy scenarios, they may fail to model typical traits of rain as water drops, and this ultimately impacts the synthetic images realism. With our method, called domain bridge, web-crawled data are exploited to reduce the domain gap, leading to the inclusion of previously ignored elements in the generated images. We make use of a network for clear to rain translation trained with the domain bridge to extend our work to Unsupervised Domain Adaptation (UDA). In that context, we introduce an online multimodal style-sampling strategy, where image translation multimodality is exploited at training time to improve performances. Finally, a novel approach for self-supervised learning is presented, and used to further align the domains. With our contributions, we simultaneously increase the realism of the generated images, while reaching on par performances with respect to the UDA state-of-the-art, with a simpler approach.
@inproceedings{wacv, title = {Domain Bridge for Unpaired Image-to-Image Translation and Unsupervised Domain Adaptation}, author = {Pizzati, Fabio and de Charette, Raoul and Zaccaria, Michela and Cerri, Pietro}, booktitle = {WACV}, year = {2020}, } -
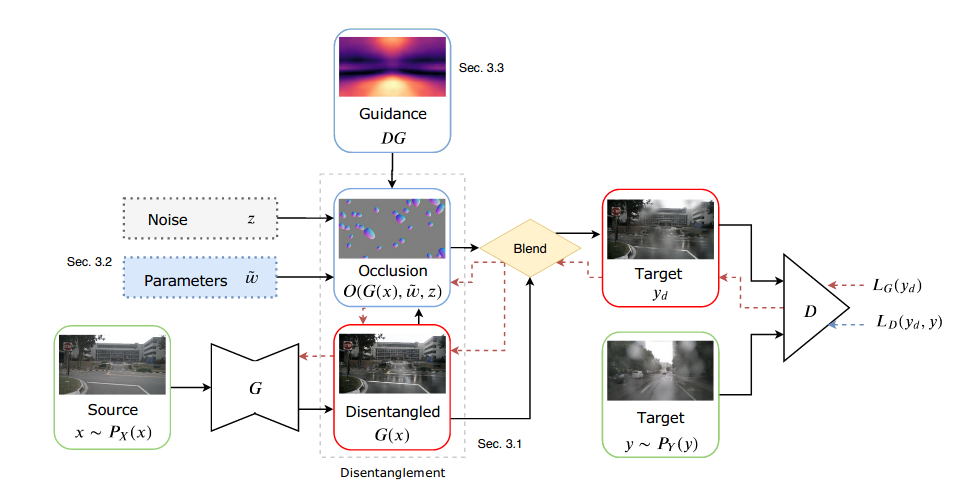 Model-based occlusion disentanglement for image-to-image translationPizzati, Fabio, Cerri, Pietro, and Charette, RaoulIn ECCV 2020
Model-based occlusion disentanglement for image-to-image translationPizzati, Fabio, Cerri, Pietro, and Charette, RaoulIn ECCV 2020Image-to-image translation is affected by entanglement phenomena, which may occur in case of target data encompassing occlusions such as raindrops, dirt, etc. Our unsupervised model-based learning disentangles scene and occlusions, while benefiting from an adversarial pipeline to regress physical parameters of the occlusion model. The experiments demonstrate our method is able to handle varying types of occlusions and generate highly realistic translations, qualitatively and quantitatively outperforming the state-of-the-art on multiple datasets.
@inproceedings{eccv, title = {Model-based occlusion disentanglement for image-to-image translation}, author = {Pizzati, Fabio and Cerri, Pietro and de Charette, Raoul}, booktitle = {ECCV}, year = {2020}, }